『社会科学のためのデータ分析入門』の第3章解答です。
繰り返しますが、自分も初学者なので間違いやミスは大いにありえます。
訂正すべきところや誤りについてはコメント欄に投稿していただけると嬉しいです。
 イワマ
イワマ
データセットを直接眺めたり基本統計量を見ておくことは問題を解くのが少し楽になる、と実感しています。
練習問題3.9.1
1
#1
> gay <- read.csv("gayreshaped.csv") > summary(gay)#省略
> #研究1の相関
> cor(gay$therm1[gay$study == "1" & gay$treatment == "No Contact"],
+ gay$therm2[gay$study == "1" & gay$treatment == "No Contact"],
+ use = "complete.obs")
[1] 0.9975817[box class="box29" title="解答"]
相関係数が約0.998であり、相関が非常に高いと言える
[/box] [say]高すぎて草[/say]2
[codebox title="R"]> #2
> 抽出
> gaytherm <- gay[gay$study == "2" & gay$treatment == "No Contact",c("therm1","therm2","therm3","therm4")]
> #研究2各波相関
> cor(gaytherm, use = "pairwise.complete.obs") therm1 therm2 therm3 therm4
therm1 1.0000000 0.9734449 0.9594085 0.9709017
therm2 0.9734449 1.0000000 0.9308287 0.9436621
therm3 0.9594085 0.9308287 1.0000000 0.9343249
therm4 0.9709017 0.9436621 0.9343249 1.0000000コントロールグループ内全ての波の相関が非常に高いと言える
イワマ
イワマ
イワマ
3
> #3
> #各派散布図
> plot(gaytherm)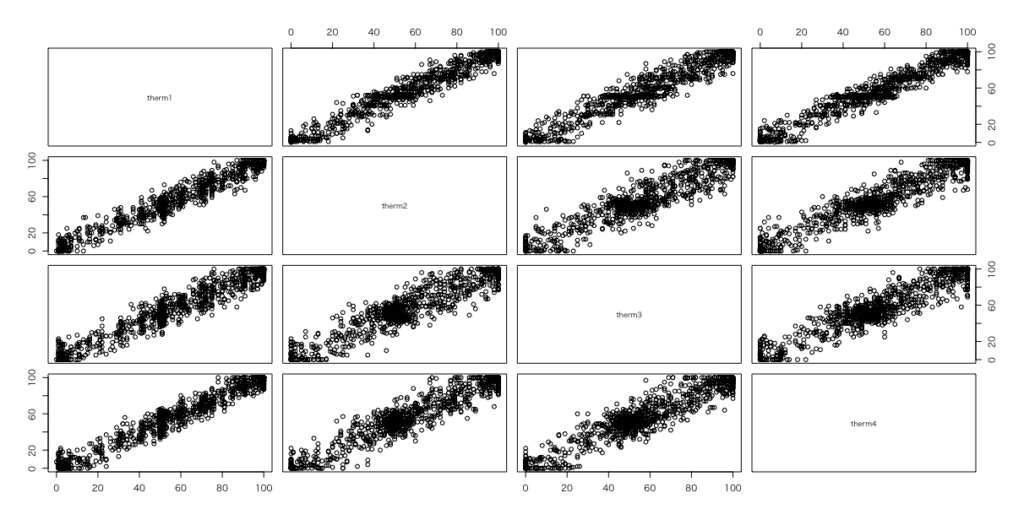
多少の外れ値はあるが、第1波と各派のペアはおおむね45度線付近にあると言える。
イワマ
イワマ
4
> #4
> ccap <- read.csv("ccap2012.csv") > summary(ccap)#省略
> #ヒストグラム
> hist(ccap$gaytherm, freq = FALSE, breaks = seq(from = 0, to = 100, by = 10),
+ xlab = "ccap", main = "Histogram of ccap")
> hist(gay$therm1[gay$study == "1"], freq = FALSE, breaks = seq(from = 0, to = 100, by = 10),
+ xlab = "study1", main = "Histogram of study1")
> hist(gay$therm1[gay$study == "2"], freq = FALSE, breaks = seq(from = 0, to = 100, by = 10),
+ xlab = "study2", main = "Histogram of study2")
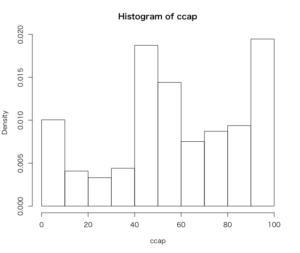
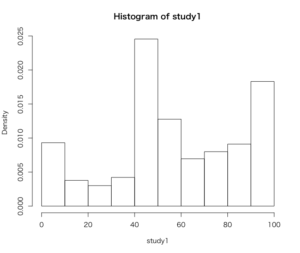
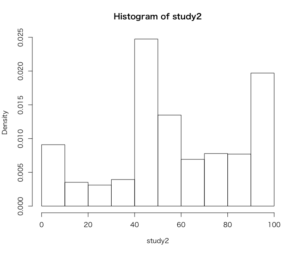
3つのヒストグラムがほぼ同様の形をしており、
同性婚研究と2012年のCCAPデータセットは分布が非常に似通っていると言える。
イワマ
5
> #5
> #QQ
> lim <- c(0, 100) > qqplot( gay$therm1[gay$study == "1"], ccap$gaytherm, xlab = "study1", ylab = "ccap",
+ xlim = lim, ylim = lim,
+ main = "qq with study1")
> abline(0, 1)
> qqplot( gay$therm1[gay$study == "2"], ccap$gaytherm, xlab = "study2", ylab = "ccap",
+ xlim = lim, ylim = lim,
+ main = "qq with study2")
> abline(0, 1)
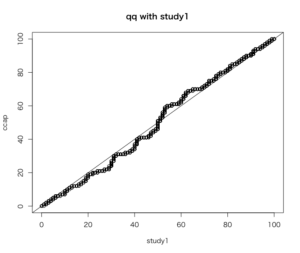
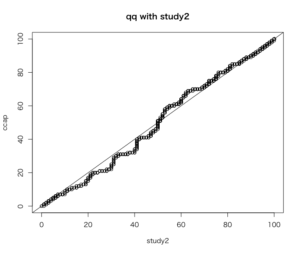
CCAPに対しての研究1、研究2のQ-Qプロットのラインは非常に似通っていると言える。
CCAP調査での同性愛カップルに対して好感度が低い人より、同性婚研究での好感度が低い人のほうが、同性婚カップルに対する好感度が低い。
また、CCAP調査での同性愛カップルに対して好感度が高い人のほうが、同性婚研究で好感度が高い人より、同性婚カップルに対する好感度が高い。
イワマ
イワマ
練習問題3.9.2
1
> #中国の自己評価
> vigselfchina <- prop.table( + table(vigchina = vignettes$self[vignettes$china == 1], exclude = NULL))
> vigselfchina
vigchina
1 2 3 4 5
0.25088339 0.22968198 0.26501767 0.15547703 0.09893993
> barplot(vigselfchina, freq = FALSE, ylim = c(0, 0.6),
+ main = "China's self", xlab = "answer", ylab = "rate of answer")
> #インドの自己評価
> vigselfindia <- prop.table( + table(vigindia = vignettes$self[vignettes$china == 0], exclude = NULL))
> vigselfindia
vigindia
1 2 3 4 5
0.51405622 0.29116466 0.11044177 0.02409639 0.06024096
> barplot(vigselfindia, freq = FALSE, ylim = c(0, 0.6),
+ main = "India's self", xlab = "answer", ylab = "rate of answer")
> #2国の自己評価平均
> tapply(vignettes$self, vignettes$china, mean)
0 1
1.825301 2.621908
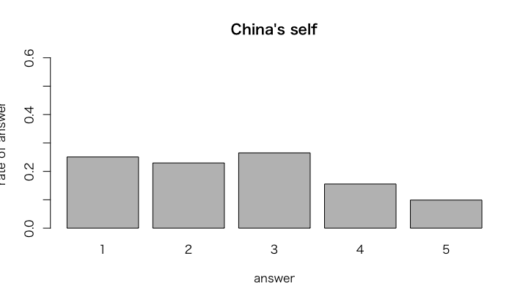
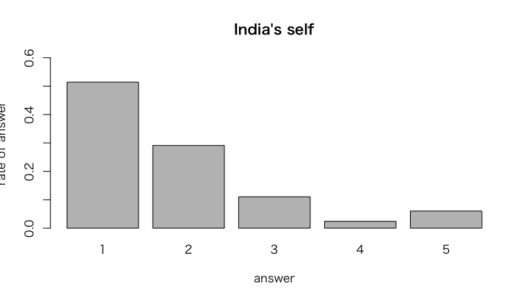
上記の結果より、インドに住む人に比べて、中国に住む人は自身の関心のある問題に政府が取り組むようにさせることに発言権があると感じていると言える。
「中国国民は現在まで公正な選挙において投票したことがない」という事実は分析結果と整合性がない可能性がある。
イワマ
イワマ
2
> #2国年齢中央値
> tapply(vignettes$age, vignettes$china, median)
0 1
35 45
> #中国年齢ヒストグラム
> hist(vignettes$age[vignettes$china == 1], freq = FALSE,
+ ylim = c(0, 0.04),
+ xlab = "age",
+ main = "China's age distribution")
> text(x = 50, y = 0.04, "median")
> abline(v = median(vignettes$age[vignettes$china == 1]))
> #インド年齢ヒストグラム
> hist(vignettes$age[vignettes$china == 0], freq = FALSE,
+ breaks = seq(from = 15, to = 90, by = 5),
+ ylim = c(0, 0.04),
+ xlab = "age",
+ main = "India's age distribution")
> text(x = 40, y = 0.04, "median")
> abline(v = median(vignettes$age[vignettes$china == 0]))
> #QQプロット
> qqplot(vignettes$age[vignettes$china == 1],vignettes$age[vignettes$china == 0],
+ xlab = "China", ylab = "India",
+ xlim = c(15, 90), ylim = c(15, 90),
+ main = "Age QQ")
> abline(0, 1)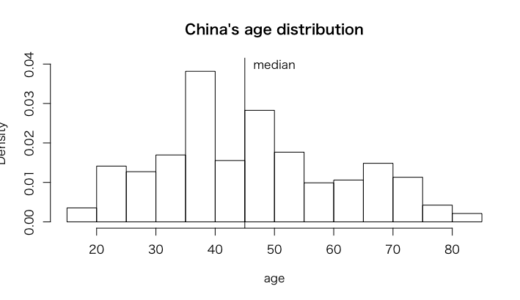
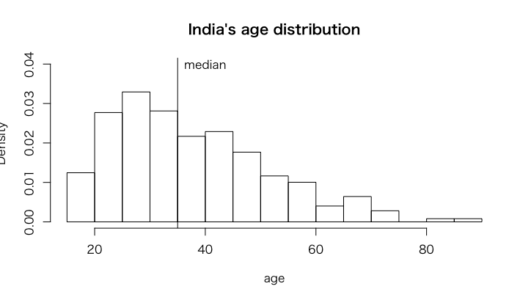
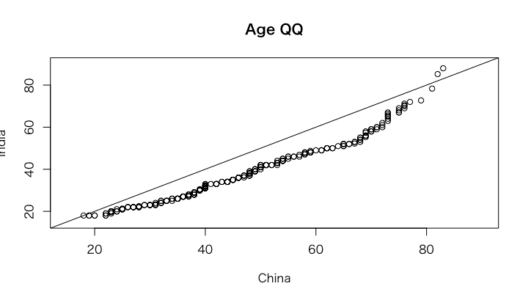
中国のヒストグラムより、インドのヒストグラムは右に裾が広がっており、回答したインド人の年齢分布がより若いと言える
またQQにおいて、ほとんどのプロットが45度線より下にきていることから、ほとんどの分位においてインド人のほうが中国人より若いと言える。
イワマ
3
> #中国
> sum(vignettes$self[vignettes$china == 1] < vignettes$moses[vignettes$china == 1])/
+ sum(vignettes$china == 1)*100
[1] 56.18375
> #インド
> sum(vignettes$self[vignettes$china == 0] < vignettes$moses[vignettes$china == 0])/
+ sum(vignettes$china == 0)*100
[1] 24.8996モーゼズより自己評価のほうが回答が低い割合は、中国が約56.184%で、インドが約24.9%であった。
中国人のほうがモーゼズより自己評価の割合が低い割合が多い。
一般的に発言権が低いと考えてしまうモーゼズの状況でも、中国人にとってはモーゼズに比べて自分の状況のほうが発言権があまりないと考えてしまう可能性が高い。
また、中国人は、モーゼズの状況でも発言権がある程度あると考えていると可能性が高い
イワマ
4
> #変数作成
> vignettes$rank <- NA > vignettes$rank[vignettes$self < vignettes$moses] <- 1
> vignettes$rank[vignettes$self == vignettes$moses |
+ (vignettes$moses < vignettes$self
+ & vignettes$self < vignettes$jane)] <- 2 > vignettes$rank[vignettes$self == vignettes$jane |
+ (vignettes$jane < vignettes$self
+ & vignettes$self < vignettes$alison)] <- 3 > vignettes$rank[vignettes$self == vignettes$alison |
+ vignettes$alison < vignettes$self] <- 4
>
> #棒グラフ作図
> vigrank <- prop.table(table(vignettes$rank, exclude = NULL)) > vigrank
1 2 3 4
0.2496799 0.1241997 0.2970551 0.3290653
> barplot(vigrank, freq = FALSE, ylim = c(0, 0.4),
+ main = "rank", xlab = "answer", ylab = "rate")
> #2国平均
> tapply(vignettes$rank, vignettes$china, mean)
0 1
2.955823 2.265018 ![]()
上記より、設問1では中国人のほうが自己評価が高いとの結論になっていたが、
ヴィニエットの質問結果と合わせることによってインド人のほうが自己評価が高い。
つまり、「中国国民は現在まで公正な選挙において投票したことがない」という事実と検証結果に整合性があると言えるだろう。
イワマ
イワマ
5
> #40歳未満
> vigrankU40 <- prop.table(table(vignettes$rank[vignettes$age < 40], exclude = NULL))
> vigrankU40
1 2 3 4
0.2109181 0.1538462 0.3076923 0.3275434
> barplot(vigrankU40, freq = FALSE, ylim = c(0, 0.4),
+ main = "rankUnder40", xlab = "answer", ylab = "rate")
> #40歳以上
> vigrankM40 <- prop.table(table( + vignettes$rank[vignettes$age > 40 | vignettes$age == 40], exclude = NULL))
> vigrankM40
1 2 3 4
0.29100529 0.09259259 0.28571429 0.33068783
> barplot(vigrankM40, freq = FALSE, ylim = c(0, 0.4),
+ main = "rankMore40", xlab = "answer", ylab = "rate")
> #平均
> mean(vignettes$rank[vignettes$age < 40 & vignettes$china == 1])
[1] 2.105769
> mean(vignettes$rank[vignettes$age < 40 & vignettes$china == 0])
[1] 2.976589
> mean(vignettes$rank[(vignettes$age > 40 | vignettes$age == 40)
+ & vignettes$china == 1])
[1] 2.357542
> mean(vignettes$rank[(vignettes$age > 40 | vignettes$age == 40)
+ & vignettes$china == 0])
[1] 2.924623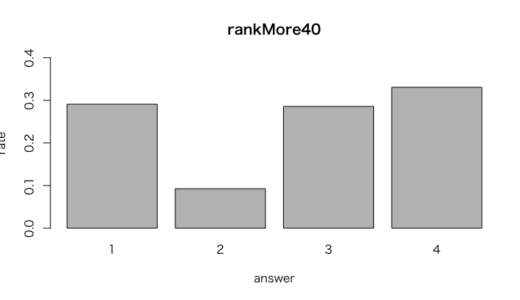
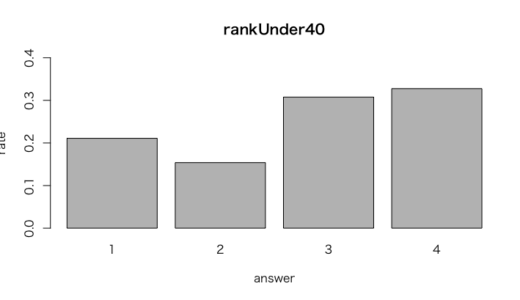
40歳以上では、中国が約2.358、インドが約2.925となり、
40歳未満では、中国が約2.106、インドが約2.977となった。
ランクの平均が40歳以上と比べて、40歳未満ではインドでは約0.05ポイント上がり、中国では約0.2ポイント下がる結果がでた。
インドでは若い人のほうが発言権を高く見積もり、中国では逆に発言権を低く見積もっている。
設問2の分析結果でインドの回答者に若い人が多かったことから、ランクづけの平均では実態より高くポイントが出た可能性がある。
とはいえ、前問の結論や解釈を大きく変えるほど、両国の世代のポイント差が大きかったとは言い難い
イワマ
練習問題3.9.3
1
> #中央値
> median(unvote$idealpoint[unvote$Year == 1980])
[1] -0.09465057
> median(unvote$idealpoint[unvote$Year == 2008])
[1] -0.425699
> #1980年分布図
> hist(unvote$idealpoint[unvote$Year == 1980],freq = FALSE,
+ ylim = c(0, 0.7),
+ xlab = "idealpoint",
+ main = "hist in 1980")
> abline(v = median(unvote$idealpoint[unvote$Year == 1980]))
> text(x = 0.2, y = 0.7, "median")
> #2008年分布図
> hist(unvote$idealpoint[unvote$Year == 2008],freq = FALSE,
+ ylim = c(0, 0.7),
+ xlab = "idealpoint",
+ main = "hist in 2008")
> abline(v = median(unvote$idealpoint[unvote$Year == 2008]))
> text(x = -0.1, y = 0.7, "median")
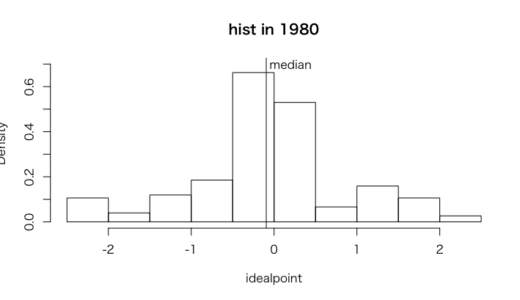
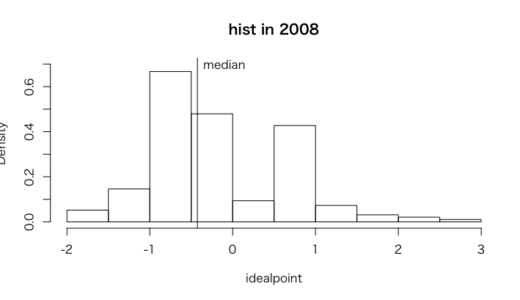
1980年に比べて、2008年のほうが全体的に理想点が低くなっている
イワマ
イワマ
イワマ
2
> #2
> #一致率グラフ
> US.mean <- tapply(unvote$PctAgreeUS, unvote$Year, + mean, na.rm = TRUE)
> RU.mean <- tapply(unvote$PctAgreeRUSSIA, unvote$Year, + mean, na.rm = TRUE)
> plot(names(US.mean), US.mean, type = "l",
+ ylim = c(0, 1), col = "blue",
+ xlab = "Year", ylab = "PctAgreeRate",
+ main = "AgreeRateTrends")
> lines(names(RU.mean), RU.mean, col = "red")
> text(2010,0.8, "RUSSIA")
> text(2010,0.15, "US")
> #新米国
> AgUS <- tapply(unvote$PctAgreeUS, unvote$CountryAbb, mean, na.rm = TRUE)
> sort(AgUS, decreasing = TRUE)
> #親露国
> AgRU <- tapply(unvote$PctAgreeRUSSIA, unvote$CountryAbb, mean, na.rm = TRUE)
> sort(AgRU, decreasing = TRUE)
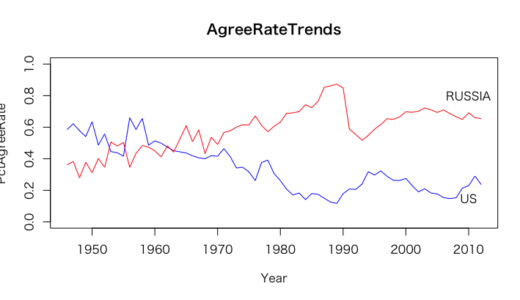
ロシアに比べて、アメリカの孤立は深まっているように見える。
もっとも新米国なのは、パラオ
もっとも新露国なのは、チェコスロバキア(現在存在していない国を含めるとドイツ民主共和国)
[/box]
3
[codebox title="コード"]
> #3
> #アメリカ
> US.ideal <- subset(unvote, select = c("Year","idealpoint"), + subset = (CountryAbb == "USA"))
> plot(US.ideal,type = "l",
+ ylim = c(-2.7, 3.1), col = "blue",
+ xlab = "Year", ylab = "IdealPoint",
+ main = "IdealTrends")
> #ロシア
> RU.ideal <- subset(unvote, select = c("Year","idealpoint"), + subset = (CountryAbb == "RUS"))
> lines(RU.ideal, col = "red")
> #中央値
> id.medi <- tapply(unvote$idealpoint, unvote$Year, median)
> lines(names(id.medi), id.medi, col = "green")
> text(2000,2, "US")
> text(2005,1, "RUSSIA")
> text(2000,-1, "MEDIAN")
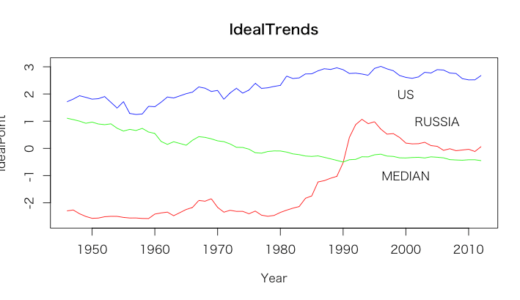
アメリカの理想点は一定して高いままだが、ロシアの理想点は前半は-2と低いが、1980年をすぎるとだんだん高くなり、現在は0付近にいる。
また、理想点の全体の中央値が1から0に下がっており、結果としてロシアと同じような投票をする国が増えたのではないかと考えられる
イワマ
4
> #4
> #旧ソ連諸国
> x <- c("Estonia", "Latvia", "Lithuania", "Belarus", "Moldova", "Ukraine",
+ "Armenia", "Azerbaijan", "Georgia", "Kazakhstan", "Kyrgyzstan",
+ "Tajikistan", "Turkmenistan", "Uzbekistan", "Russia")
> PreRU <- subset(unvote, select = c("PctAgreeUS","idealpoint"),
+ subset = ((Year == 2012) & (CountryName %in% x)))
> otherRU <- subset(unvote, select = c("PctAgreeUS","idealpoint"),
+ subset = ((Year == 2012) & !(CountryName %in% x)))
> plot(PreRU,
+ xlim = c(0, 1),
+ ylim = c(-2.7, 3.1), col = "red",
+ xlab = "PctAgreeUS", ylab = "IdealPoint",
+ main = "ideal & PctAgreeUS distribution")
> points(otherRU,col = "blue")
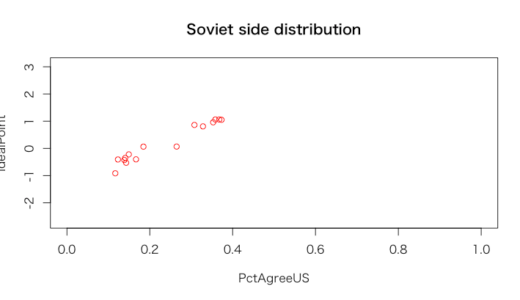
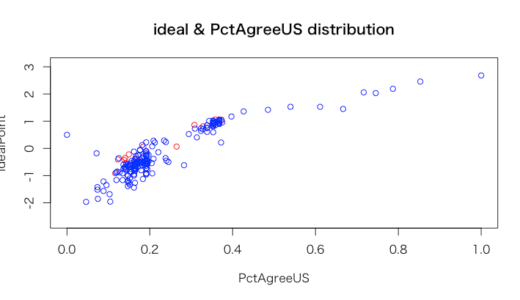
2012年では旧ソ連諸国では、理想点が高くアメリカと一致率が高い国もあれば、理想点が低くアメリカと一途率が低い国もあり、同じようなイデオロギーではなくなっている。
しかし他の諸国と比べてみるとそこまで大きく全体のトレンドと相反してはいない
イワマ
5
> #5
> PreRU2 <- subset(unvote, + subset = (CountryName %in% x))
> RU.T <- tapply(PreRU2$idealpoint,
+ PreRU2$Year, median, na.rm = TRUE)
> plot(RU.T,
+ type = "l",
+ ylim = c(-2.7, 3.1),
+ col = "red",
+ xlab = "Year",
+ ylab = "IdealPoint",
+ main = "Idealpointtrends",
+ xaxt="n")
> otherRU2 <- subset(unvote, + subset = !(CountryName %in% x))
> otherRU.T <- tapply(otherRU2$idealpoint,
+ otherRU2$Year, median, na.rm = TRUE)
> lines(otherRU.T, col = "blue")
> abline(v = 43)
> text(46,3,"1989")
> text(60,1,"Soviet")
> text(60,-1,"otherSoviet")

前半では旧ソ連諸国は理想点は-2点以下と低く、それ以外の国の中央値は1点付近と高かった。
冷戦が終了する1989年前後で旧ソ連諸国は急激に理想点が高くなり、その他のくにもゆるやかに理想点が低くなったため、
現在の理想点は旧ソ連諸国とその他の諸国とでの差は少なくなった
イワマ
6
> #6
> #2変数結合
> ideal1989 <- cbind(unvote$idealpoint[unvote$Year == 1989],
+ unvote$PctAgreeUS[unvote$Year == 1989])
> ideal2012 <- cbind(unvote$idealpoint[unvote$Year == 2012],
+ unvote$PctAgreeUS[unvote$Year == 2012])
> #k平均法
> kideal1989 <- kmeans(ideal1989, centers = 2,nstart = 5)
> kideal2012 <- kmeans(ideal2012, centers = 2,nstart = 5)
>
> plot(ideal1989, col = kideal1989$cluster + 1,
+ xlab = "idealpoint",
+ ylab = "PctAgreeUS",
+ main = "Idealogical distribution in 1989")
> plot(ideal2012, col = kideal2012$cluster + 1,
+ xlab = "idealpoint",
+ ylab = "PctAgreeUS",
+ main = "Idealogical distribution in 2012")
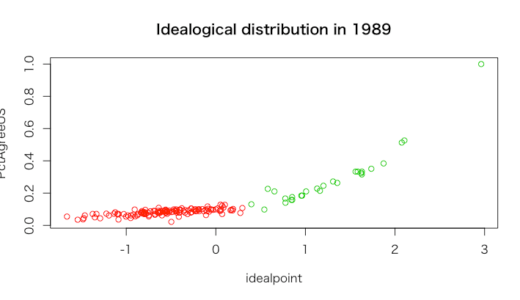
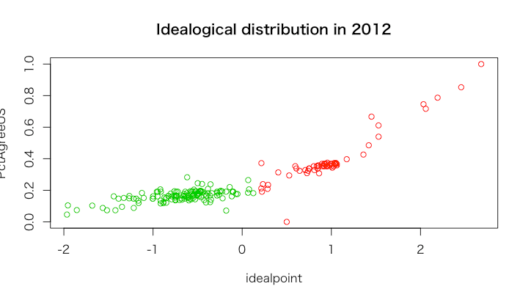
理想点が低くアメリカと投票一致率が低い陣営と、理想点が高く投票一致率が高い陣営とで、
世界はいまだに2つの陣営に別れていると言える
イワマ
イワマ

ありがとうございます!
結果は同じになりました
下巻の第1章の答えだしていただけると助かります…!
3章ありがとうございます。
このテキストの下巻の5章(最初の章)の解説をしていただけると助かります。ぜひともよろしくおねがいします。